kaiyun(中国)2026世界杯手机APP下载 桥介数物尚阳星: 高质地的跨骨子全身绽开数据不可依靠简便收集


当宇树用侧空翻和功夫向专家评释了其顶尖的小脑武艺,当星河通用、星海图、千寻智能等公司正在把“通器具身大脑”推成行业的主流叙事。一切看起来言之成理——绽开武艺解决了,接下来等于大脑竞争的期间了。
但这里有一个被公众集体忽略的事实:宇树(们)治理了,不代表行业解决了。绽开终结从未成为一个被无为解决的问题,它仅仅极少数公司的专有武艺。
推行情况是:头部具身大脑公司从来不把绽开终结当作他们我方的主场,它们的策略是绕开宇树最强的壁垒,先作念轮式或固定底盘机器东说念主。中庸东说念主形骨子公司在绽开终结上的追逐则更为忙活。而念念作念“机器东说念主界的苹果”的宇树,或者率恒久不会作念跨型号适配的通用绽开终结平台。
是以,不管是头部具身大脑公司,如故中小骨子公司,绽开终结是它们朝夕必须要补的一课。
统统具身行业在数据收集的时势上,也呈现出白璧青蝇的相反。由于“大脑”公司密集扎堆,第三方数据工场为了追求规模效应,将绝大多数产能歪斜在操作数据领域(Manipulation)。比拟之下,感奋潜入底层“小脑”的厂商稀稀拉拉,导致绽开数据(Locomotion)在买卖上因需求规模不及,空乏第三方干事商感奋为其干事。这迫使聚焦绽开终结的厂商只可在市面上采买脱落数据,更多的是依靠自有团队进行自采。这种供给侧的差错,使得绽开终结领域的数据愈加稀缺,而且高质地、高泛化的数据就更为匮乏。
“近两年,头部具身智能骨子厂商与上游企业已陆续把“数据”列入政策议程,仅仅这股趋势在不同方进取的落点并不平衡——绽开终结关联的数据建设于今已经一派彰着的凹地,甚而不错说是“真旷地带””桥介数物的创举东说念主尚阳星对创投家暗示,“行业内现存的绽开终结数据广泛存在供应不及、质地狼藉不皆、构型与场景局限性大等问题,远远跟不上模子磨练所需的规模。”
近日,专注于通用机器东说念主绽开终结基础递次的研发商——桥介数物,晓谕其自建的“跨骨子全身绽开数据工场”细密过问使用。而这个数据工场恰是为了解决行业“高质地的跨骨子全身绽开数据”的缺位而建。
尚阳星诞生于1999年,华科本科,南科大保研,师从逐际能源创举东说念见识巍阐发注解。桥介数物是他的第一个创业技俩,团队从寝室起步,2023年底拿到奇绩创坛的种子轮投资后,从2024年底到2025年8月的半年内,连络完成天神轮、天神+轮及Pre-A轮,累计金额近亿元——正轩投资、复星创富、潜能集团、隐山本钱、明荟致远、沂景本钱等机构接踵入场。

在具身智能这个广泛耗费的赛说念里,桥介数物成立第一年就接到了客户技俩,达成了盈利。2024年8月的寰宇机器东说念主大会上,27家东说念主形机器东说念主厂商参展,桥介数物干事了其中跨越半数。对于一台未经调试的东说念主形机器东说念主,它最快一周能完成模子磨练,让它走起路来。一个定制化技俩每每需要1到3个月。
近日,我们借着桥介数物“跨骨子全身绽开数据工场”细密启用的机会,与这位99年的年青创举东说念主,就绽开数据的质地、泛化、磨练等问题,伸开了一次深度的对话。
▎以下为与尚阳星的对话全文,略有删减:
创投家:您先帮我们界说一下什么叫“高质地的跨骨子全身绽开数据”?高质地高在哪?
尚阳星:要回报这个问题,先要回报“我们念念要什么绽开武艺”。
对通用全身绽开模子来说,我们要的是一种能够进取兼容多模态动作意图、向下兼容不同骨子硬件、安全可靠、而且不错在复杂环境中连接进化的绽开武艺。
而这种武艺对数据建议了更高的要求:不是孤独的绽开轨迹,而是能同期保留全身协同、任务意图、战役相关、环境高下文、物理可行性和跨骨子复用价值的数据。
创投家:现存的绽开数据形态存在哪些问题?
尚阳星:现存的数据形态,单独看都很难当然骄慢这些要求:
动捕数据不错准确、结构化地记载东说念主体绽开景色,但缺失环境信息以及东说念主和环境之间的精准交互;遥操作数据严格绑定特定机器东说念主骨子,硬件一换,复用价值就会显耀下跌;第一东说念主称视频麇集在终局和物体交互,不可完好抒发躯干、下肢、重点和战役之间的全身互助相关;第三东说念主称视频固然能看到举座动作,但难以从中索要出准确合理的东说念主体动作。
这些数据各自都有价值,但单独都不及以救援通用全身绽开模子需要的数据闭环。
创投家:是以通过我们数据工场产出的数据是一种若何的形态?
尚阳星:我们把信得过面向通用全身绽开模子磨练的数据钞票,界说为跨骨子全身绽开数据(Cross-EmbodimentWhole-BodyMotionData,CWM),要求CWM至少同期骄慢以下四个性质:
跨骨子可重定向性(Cross-embodimentretargetability)。褪色段动作必须能够通过长入的处理管线,在相反显耀的多种骨子上,产出物理自洽的磨练样本。
全身障翳性(Whole-bodycoverage)。数据必须完好抒发躯干、算作、手部、手指以及它们之间的协同相关,而不可只保留上半身终局轨迹或下半身步态。
物理可行性(Physicalfeasibility)。一条及格的数据,不仅仅绽开学平滑合理,还需在筹画骨子上的能源学具备物理可行性,不可出现浮空、穿透、滑移、失稳、力矩超限等问题。
多模态性(Multi-sourceaugmentability)。及格的数据还需要同步收集东说念主体动作、语义标签、第一东说念主称视频、第三东说念主称视频、环境钞票和物体钞票。
骄慢这四个性质的CWM数据,不是简便收集就能获得,它需要许多的后处理武艺被坐褥出来,这亦然我们建设跨骨子全身绽开数据工场的起点。
创投家:为什么说CWM数据“不是靠收集就能获得”?
尚阳星:对于全身绽开终结来说,数据要障翳的不仅仅几个法度动作,而是行走、回身、下蹲、搬运、捏取、救援、避障、复原平衡、战役切换等大宗连络动作组合。
我们里面的判断,要磨练出一个信得过通用的全身绽开模子,最终需要数十万甚而上百万小时级别的高质地CWM数据。在这个量级面前,极少数据在经久来看很难救援起通用化,信得过有价值的是能够禁止延迟的数据规模。
全身绽开数据的复杂性在于,它不是“收集的动作越多越好”,而是必须有正确的数据配方和严格的数据质地终结。同期,每条数据还必须经过清洗、标注、重定向和物理考据。不然,大规模数据很容易变成大规模噪声。
因此,CWM数据坐褥必须被设想成一套工业化坐褥体系,而收集仅仅其中一环。

创投家:这套工业化坐褥体系具体包含哪些递次?
尚阳星:一段动作从被设想出来,到能进入磨练集,还必须经过质检、跨骨子重定向、能源学与仿真增强、语义标注,以及来自模子磨练侧的反馈闭环。
这其中,专科动作设想东说念主员负责界说动作谱系,收集团队负责高质地同步录制,工程团队负责清洗、神志化、重定向和仿真回放,算法团队负责物理考据、磨练反馈和数据筛选,kaiyun(中国)2026世界杯手机APP下载质检团队负责把不可用样本挡在磨练集除外。
这亦然CWM数据工场的中枢价值:用瓦解的地方、开导、活水线、专科团队和质检体系,把通用全身绽开数据变成一种可连接坐褥武艺。
创投家:数据工场在设想动作这个递次上是如何操作的?
尚阳星:通用全身绽开模子需要一套连接扩展、能障翳躯壳协同方式的绽开空间。这套空间不可仅仅动作目次的堆叠,而要沿几条互相安适的干线填充。
领先等于按躯壳使用方式组织,而不是按动作称呼充数。移动、姿态调理、肢体协同、战役切换和物体操作,这些基础维度是后续复杂武艺的底盘。
其次我们会兼顾复杂地形、多东说念主交互与环境交互。复杂地形改换救援策略,多东说念主交互引入空间协商,环境交互让躯壳绽开与物体、战役面和可达空间深度耦合。它们不可靠幽谷单东说念主动作外推,必须显式安排进收集谋略。
第三,我们也会保留住意志举止与摆脱阐述。脚本只界说任务界限,确凿绽开里还有大宗没被写下来的部分:个体动气派俗、临场调养和搪塞不测的本能响应。专科动作设想东说念主员会在录制中给出意图与料理,同期保留扮演者按自己风气完成动作的空间。
第四等于动作复原与失败兜底。模子能不可被部署,很猛进程上取决于失败时能不可稳住。失衡后的再平衡、碰撞后的避障回缩、非理念念姿态下的起身复原,这类样本每每稀缺,但径直相关到模子的安全界限。

创投家:CWM数据在收集历程中需要同步收集多形态的数据,这个收集历程是如何达成的?
尚阳星:对,CWM的同步收集不是单纯录一段东说念主体动作,而是要在褪色段动作中同步回报四件事:绽开意图、躯壳绽开方式、交互筹画与环境。这自然要求东说念主体动作、视频、语义、场景被同步记载。
按刻下的收集范例,一条完好记载会尽量同步收集以下四类数据:
东说念主体动作(BVH),承载动作语义、躯壳协同、重点变化和姿态调理;
原始视频,作为高价值的援救信号,救援视频动作补全与东说念主体动作索要,包含第一东说念主称和第三东说念主称视角;
AG真人2026世界杯中国官网场景交互钞票,提供动作发生的环境与物体高下文,是把动作放进仿真环境的前置要求。主要收集两类:地形与场景钞票、可交互物体钞票。
语义标签,由专科动作设想东说念主员、现场记载员和AI标注系统协同生成,界说动作界限、动作类别、场景和意图。
之是以必须同步收集,是因为全身绽开的价值不在某一个单独模态,而在不同模态之间的对应相关。若是这些信号莫得对皆,我们就无法判断手部轨迹对应的是哪一帧物体战役,也无法判断脚底受力是否对应刻下姿态,更无法考据这段动作是否真的不错进入磨练集。为此,数据工场为通盘收集开导建立了长入的收集时钟和时刻戳体系,来保证其对应相关。
创投家:对于跨骨子重定向这个递次,面前行业里通用的解决有筹画是什么?我们又是如何解决的?
尚阳星:重定向(motionretargeting)是把一段以东说念主体或某一参考骨子为坐标系的动作,转机为筹画机器东说念主骨子上的轨迹。业内广泛的操作方式是以东说念主工为主的调参历程,每个型号的机器东说念主都需要单独调试,只斟酌重定向这个递次,劝诫丰富的东说念主或者也需要糜费几个小时/台。
而面前行业通例作念法最大的问题在于:只斟酌了绽开学,而莫得斟酌能源学。这就导致重定向仅仅师法了动作开动的轨迹,而莫得综认为议骨子的质地,轴距,摩擦力等身分,其终结等于跨骨子泛化进程不达预期。
我们在算法层自研了重定向引擎,救援“大肆动作×大肆机型×大肆地形”。输入同步收集的多维度数据,就不错输出适配各种骨子,而且综认为议了地形、战役与要道身分的有用终结。工程层上,长入骨子轮廓层让新机器东说念主仅靠URDF即可自动适配。而且,工场采取了流式与离线双模式,救援边采边重定向,将逐条东说念主工调试的职责压缩至接近及时完成。

创投家:重定向之后的数据就不错径直用于模子磨练了吗?
尚阳星:还有一个递次叫数据增强。
跨骨子重定向输出的是高质地候选轨迹,但候选轨迹还不是最终磨练钞票。数据增强要作念的是链接把这些候选轨迹变成更可考据、更可磨练、更容易被模子消费的数据。
我们沿三条旅途优化这些轨迹:能源学增强、仿真各样性增强、语义标注。
能源学增强:把优质样本放进筹画骨子的能源学与战役模子里,通过RL能源学后处理同期终结追踪盘曲和物理抵牾,让候选轨迹从“绽开学上像”升级为“在筹画骨子上能追踪、不穿透、不超扭矩、不违背摩擦锥”。
仿真各样性增强:把褪色段动作放进不同的假造环境里反复履行,让CWM钞票的障翳密度成倍放大。补皆缺失模态,同期扩增视觉与场景各样性。
语义标注:AI标注系统援救生成动作切片、动作类别、战役景色、场景对象、任务语义、失败原因和武艺维度等标签,由专科动作设想东说念主员负责复核。
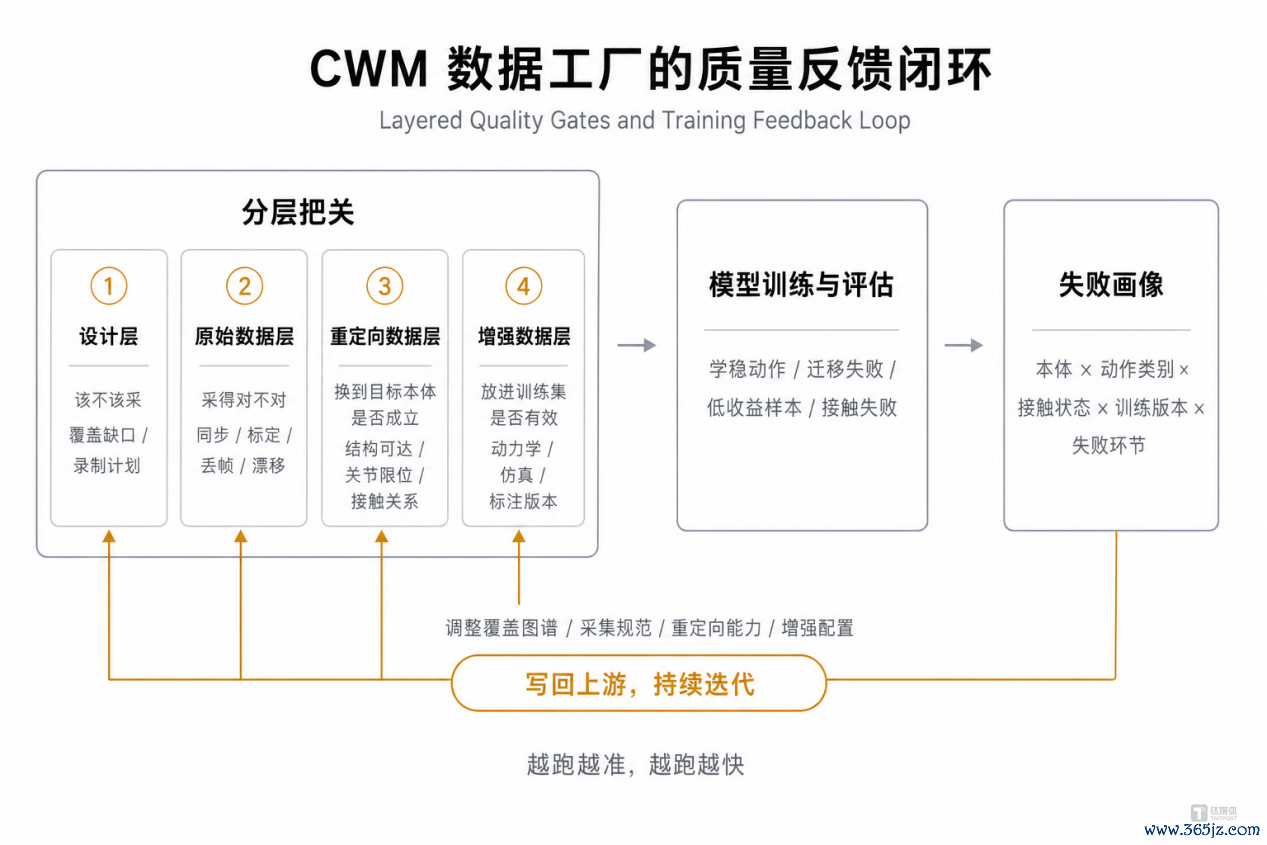
创投家:工场临了如何考据数据钞票的有用性?
尚阳星:CWM数据工场的质地管理则要走两步:先沿坐褥链路作念分层把关,再用模子磨练的终结作念闭环反馈。
一条样本从动作需求走到磨练集,要规则通过四说念安适的质检,也等于之前的设想层、原始数据层、重定向层和增强数据层。四层把关共同把一条候选样本筛成可入磨练集的钞票,但信得过能不可磨练出通用全身绽开武艺,最终只可由模子告诉我们。
磨练侧会把每一次模子评估终结,汇总成一份可回写的失败画像。失败画像会被径直写回到上游每一层,每一层再凭证这份失败画像调养每一步的履行策略。
两步合在通盘,数据工场就酿成了连接迭代闭环,将数据置于“设想—收集—处理—磨练—反馈”的闭环链路中,从而提高单条数据的有用欺诈率,让数据价值获得最大化开释。
创投家:面前数据工场的成本结构是若何的?运营景色如何?产出如何样?
尚阳星:当今工场或者有几十名职工,地方规模或者是1000平米附近。算上开导的采购以及运营成本,举座过问在千万级别。收集成本或者是数百元/小时。
夙昔三个月,我们在里口试点中跑通了跨骨子全身绽开数据工场的端到端链路。沿着这条链路,我们累计产出了近千小时的高质地CWM数据。用这批数据训出的全身绽开模子,最终在十多款结构、驱动性能、质地散播和惯量散播相反显耀的足式机器东说念主上完成了枢纽考据。
下一阶段的重点,是从试点考据转向规模化坐褥。我们会把地方、收集棚、动捕开导、动作设想团队、扮演者编制和算法/仿真/磨练算力集群同期扩容,让前边跑通的产线在更大规模上瓦解运转。我们的筹画是在新工场落地后,早期阶段要酿成每月数千小时级、面向多构型机器东说念主的高质地CWM数据产出武艺。
创投家:数据工场对于行业的价值是什么呢?
尚阳星:我们作为安适第三方的绽开模子提供商,以及畴昔的通用操作系统提供商,我们的筹画是面向全行业、适配通盘机器东说念主。若是莫得我们这么的第三方变装存在,每家公司念念要达到一流的绽开终结终结,可能就必须我方来建数据工场,或者把这类数据集都买一遍。这个成本当下就得几千万,可能过一段时刻会更多。
另外,当今行业里有几百家东说念主形机器东说念主公司kaiyun(中国)2026世界杯手机APP下载,我们揣度即使畴昔最终料理,至少也会存在几十家,不错对标汽车厂商的数目。若是每家公司都重新来一遍,这是弘大的资源浪费。